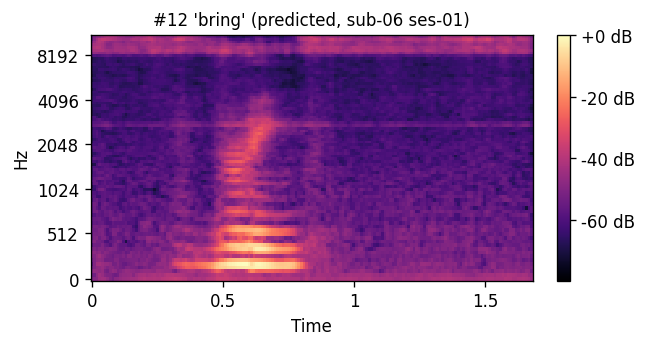
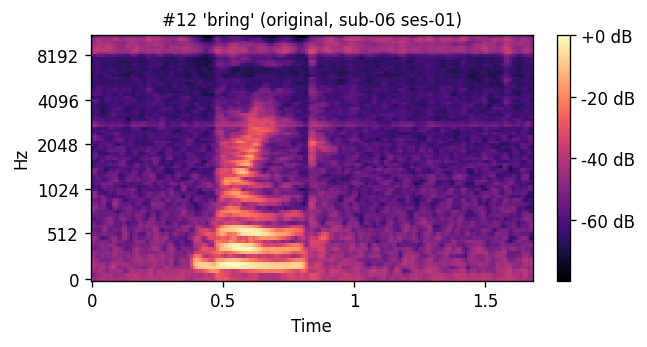
sub-06 / ses-01
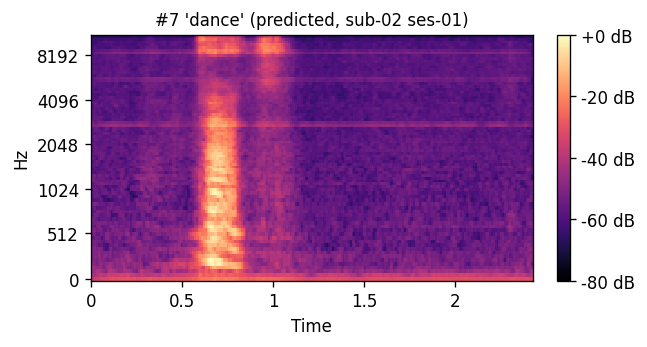
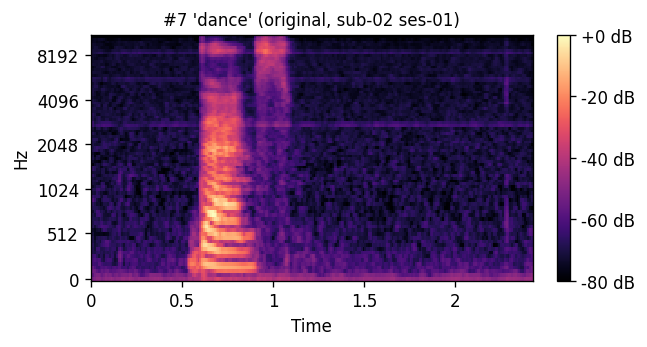
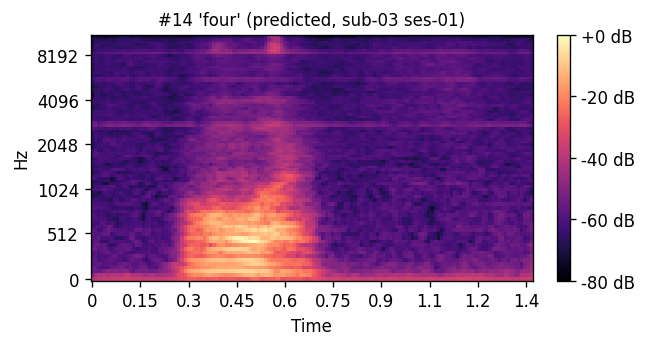
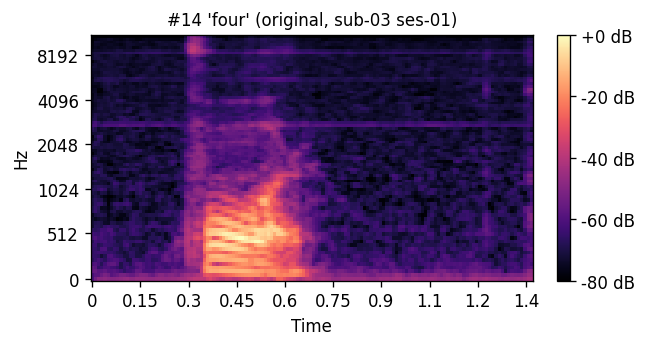
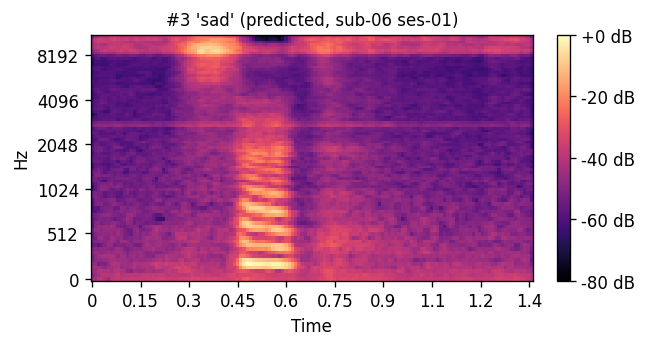
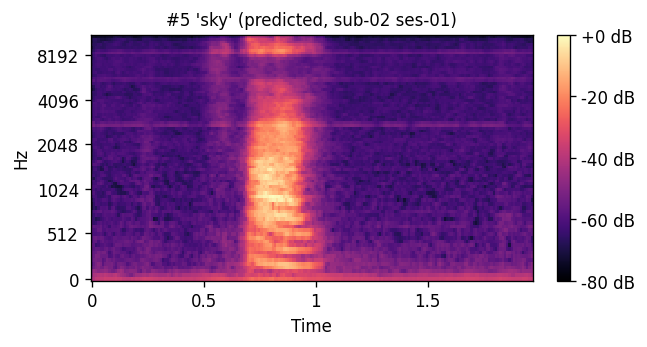
PREDICTED synthesized from ultrasound
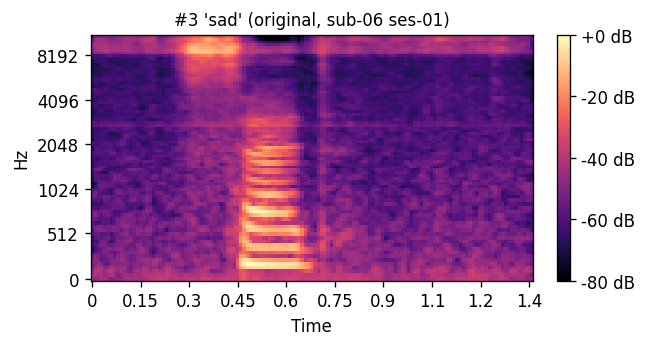
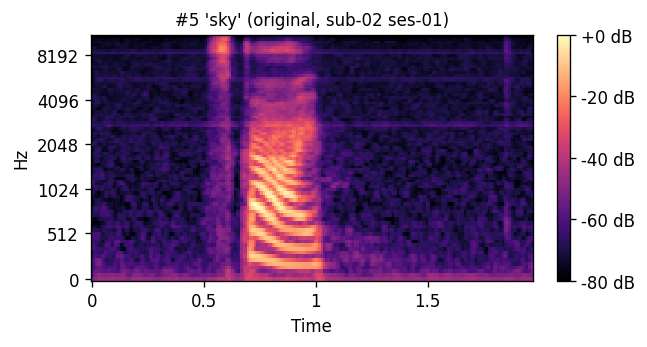
ORIGINAL natural recording
Supplementary material — Frigyes Viktor Arthur and Dávid Sztahó
Manuscript submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing.
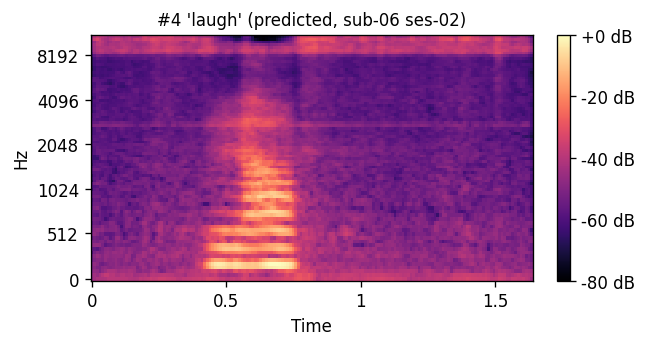
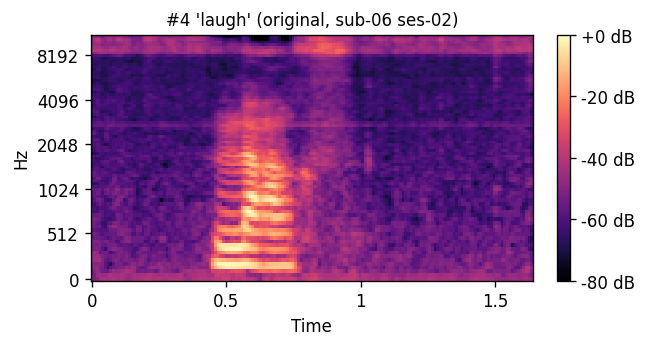
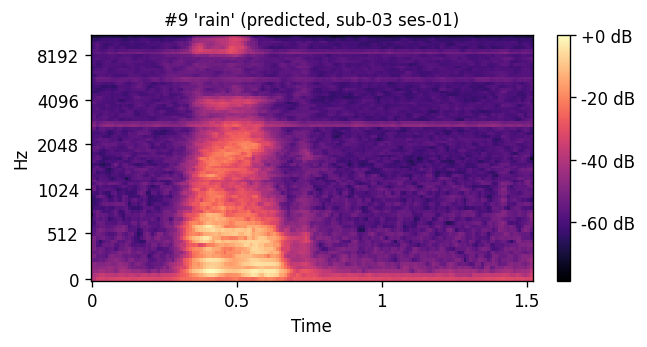
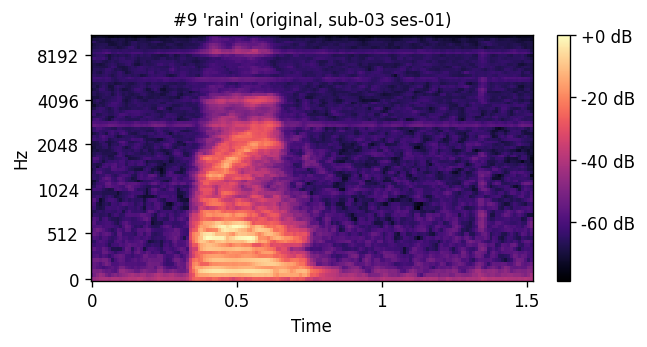
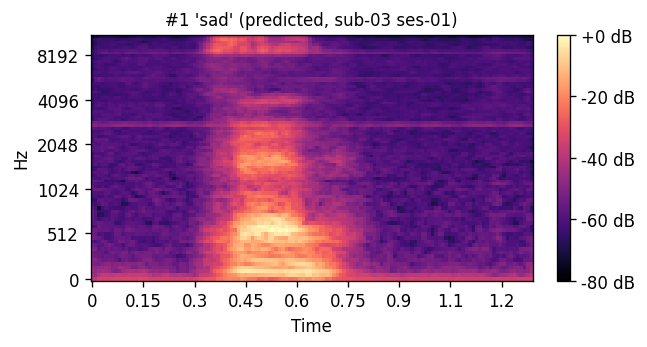
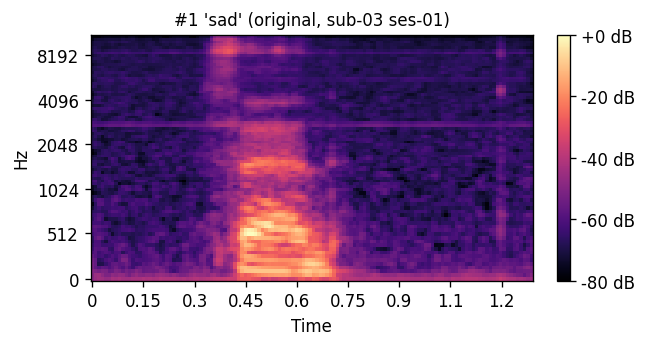
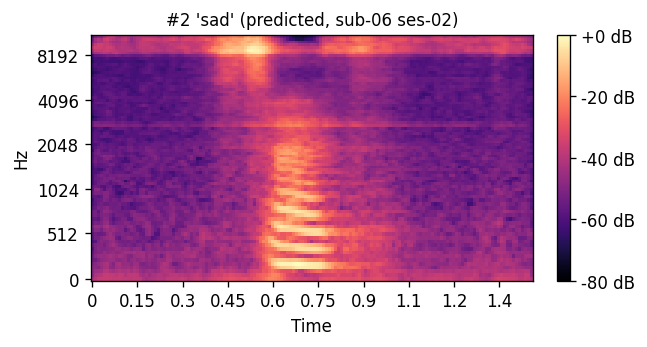
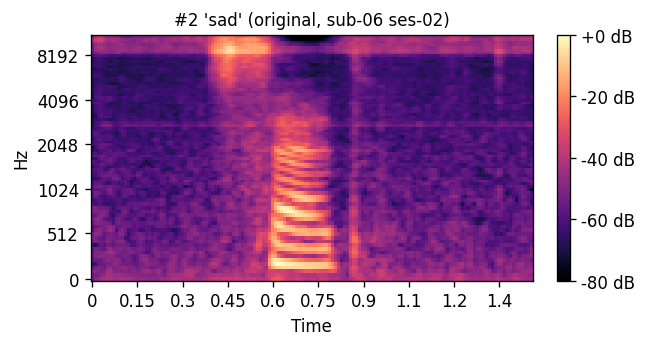
A short window of ~40 raw ultrasound frames (~500 ms) is processed by a convolutional encoder, aggregated, and decoded into an 80-channel mel-spectrogram frame; a pre-trained WaveGlow vocoder then converts the predicted mel-spectrogram into an audible waveform. The same vocoder is applied to the natural-speech reference, so listening tests compare two conditions that differ only in the AAM stage (matched-vocoder protocol).
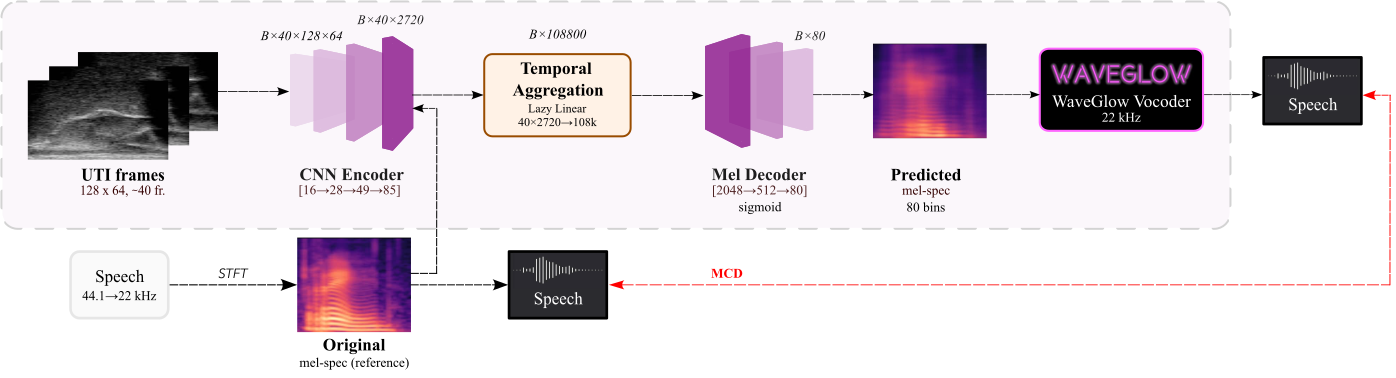
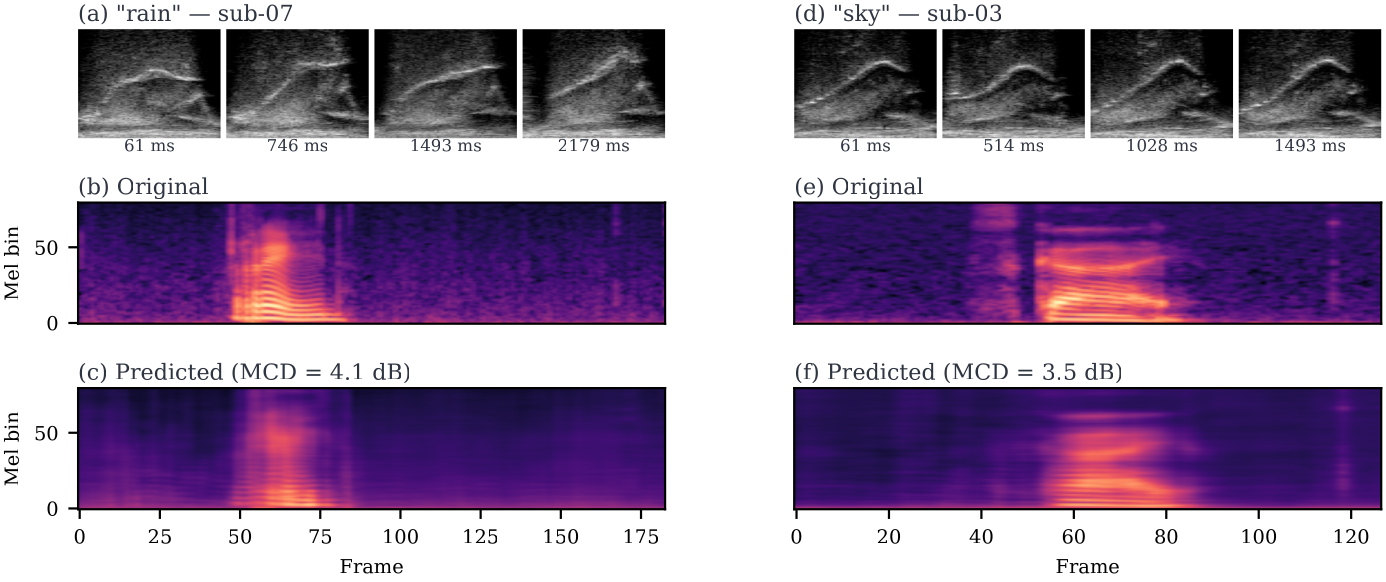
Articulatory-to-acoustic mapping (AAM) — reconstructing speech from articulator measurements — is a core building block for silent speech interfaces (SSIs). Most ultrasound tongue imaging (UTI)-based AAM systems predict classical vocoder parameters (MGC, LSP, F0) that require brittle voicing/pitch decisions and bypass modern neural waveform generators. We propose a temporal convolutional network that maps short windows of UTI frames directly to 80-channel mel-spectrograms, inverted to a waveform by a pre-trained WaveGlow vocoder. The system is trained and evaluated on a custom multimodal corpus of four speakers across three sessions each (1,200 utterances of isolated English words; Hungarian L1 / English L2). The same vocoder is applied to natural and predicted mel-spectrograms, so vocoder artifacts are shared across conditions and the evaluation isolates the AAM stage. With this matched-vocoder protocol the system reaches a mean Mel-Cepstral Distortion of 4.46 dB, with no significant inter-speaker differences (p = 0.838). A blinded 8-alternative forced-choice listening test with 31 listeners (1,240 trials, IEEE Std 1329 conformant) reaches 84.0% word recognition accuracy for synthesized speech against 99.7% for natural recordings (Cohen’s h = 0.71), a Word Error Rate of 16.0%, macro-AUC of 0.895, and substantial inter-rater agreement (Fleiss’ κ = 0.75). Recognition errors are phonetically structured and concentrate on minimal pairs such as door–four, consistent with the limited visibility of the tongue tip and lips in midsagittal UTI. The matched-vocoder protocol and the listener-response data are released, providing a reproducible reference point for UTI-based AAM and a foundation for cross-speaker pooling, continuous-speech extension, and target-population studies.
PREDICTED — synthesized from ultrasound ORIGINAL — natural recording
Until the article is published, please cite this repository directly via the
GitHub “Cite this repository” button (powered by the
CITATION.cff
file)
or use the placeholder BibTeX entry below:
@unpublished{arthur2026directaam,
author = {Arthur, Frigyes Viktor and Sztah{\'{o}}, D{\'{a}}vid},
title = {Direct Articulatory-to-Acoustic Mapping from Ultrasound Tongue Imaging},
year = {2026},
note = {Manuscript submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing.}
}
Unless otherwise stated, the contents of this site and the linked repository are released under Creative Commons Attribution 4.0 International (CC BY 4.0).